pythonでデータの可視化というとplotlyやらjupyter notebookを思い浮かべる方が多いかもしれませんが、
streamlitを使ってみるととてもいい感じでした。
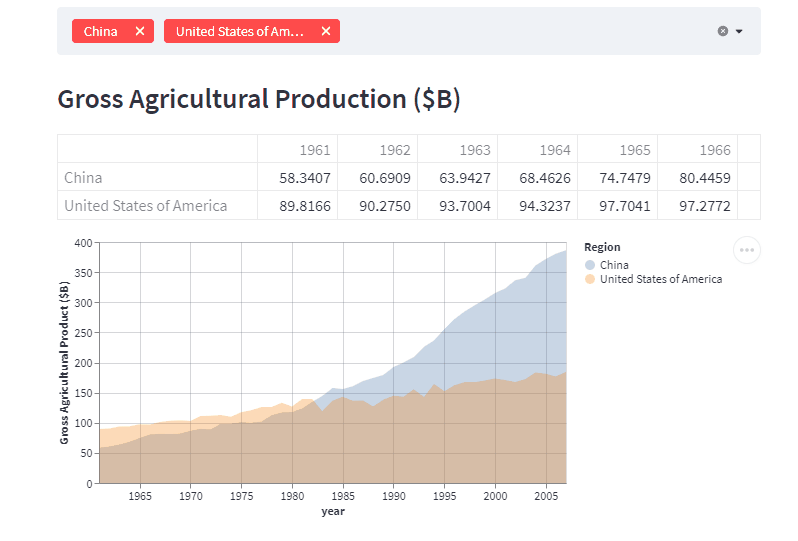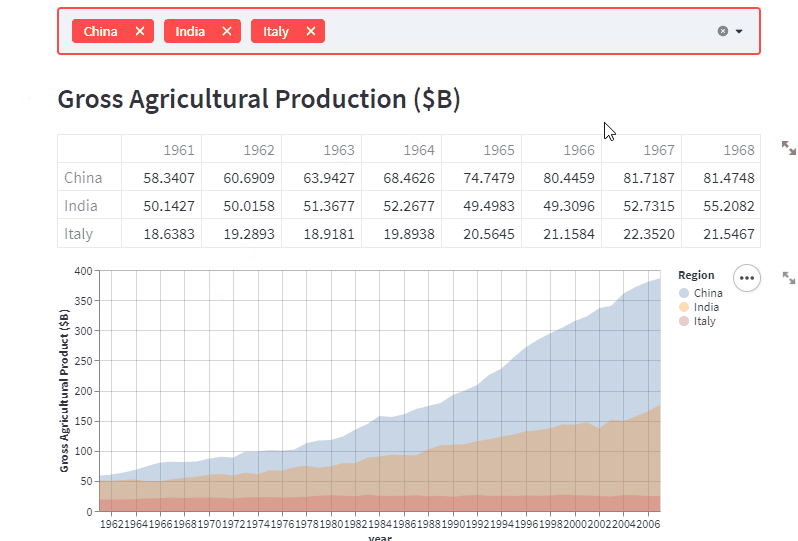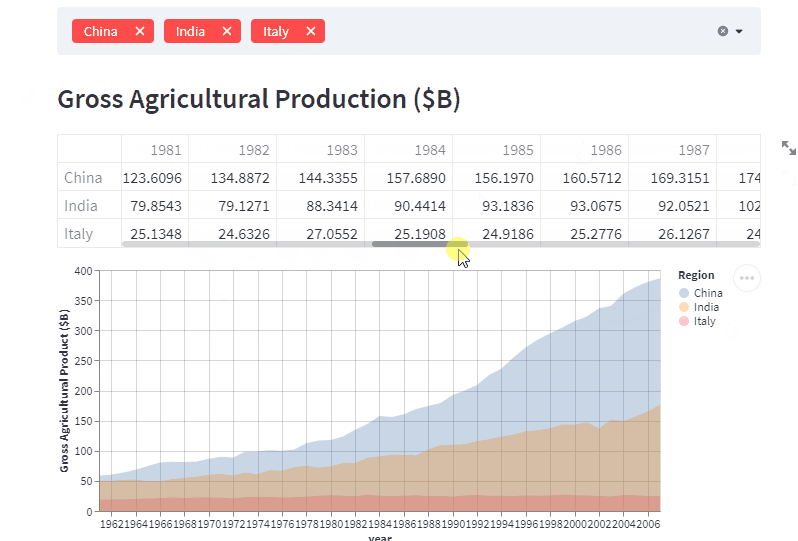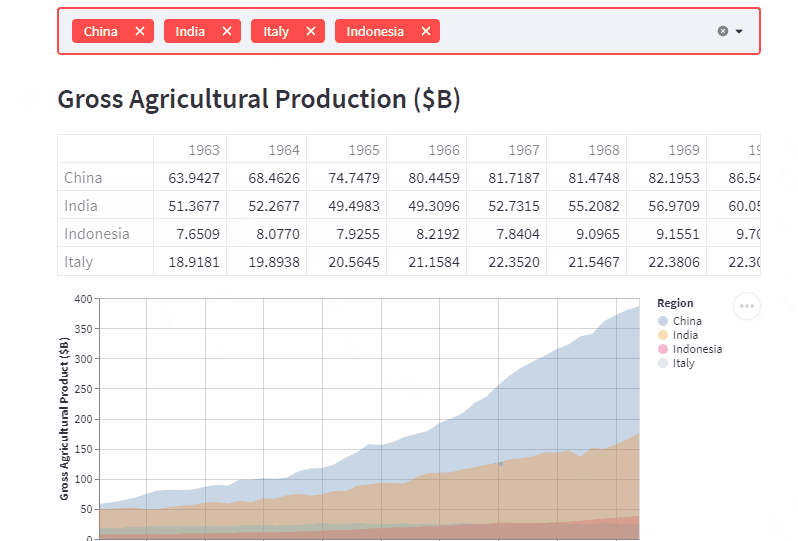
こんな感じのデータ可視化webアプリケーションが数十行で作成できます。
データのフィルタリングや再描画をしてくれるwebアプリケーションをイチから作ろうと思うと、めちゃくちゃ大変ですよね。
使い方も簡単なので、興味をもっていただけたら嬉しいです。
stream litのとは
streamlitの長所は何と行っても複数人で共有しやすいということでしょうか。
ローカルサーバーを立てるので、ブラウザからデータにアクセスしてもらうことができます。
notebook との使い分けとしては、非エンジニアでも使いやすいということでしょうか。
簡単なボタンの配置やリストの配置はすぐにできるので、
アクセスした人が見たいと思うものを柔軟に提供することができます。
しっかりした準備をしておけばプレゼンの補足資料としても使えると思いますよ
こんな感じで見たいデータだけを表示するアプリケーションを簡単に作ることができます。
単独のサイトの運用にはおすすめしない
あくまで、アクセス数が限定されたところでの運用がよいでしょうね。
可視化までが早いといっても、一般のwebアプリケーションを作ろうとした場合は、ログイン認証やデータベースへのアクセスの仕組みが必要になってきます。
きちんとした評価はしていませんが、そうしたことをするならdjangoなどのwebアプリケーションを使った方が効率的と思います。
アクセス負荷やアクセス速度はおそらく最適化されていないと思うので。
公式が運営する環境でのデプロイやgithubではアプリケーションを運用することができますが、手段が限定されてしまっているので、あくまでシステム要求としてそれで問題がない方に限られると思います。
自社サイトのドメインに開設したいとか、アクセス制限を加えたい!とかそういったことをしたい場合は、他のアプローチを取った方が良いと思います。
stream lit の使い方
まずは、基本的な使い方から記載したいと思います。
基本的なpythonの開発環境の構築方法に関しては割愛したいと思います。
Linuxならばデフォルトでpythonが導入されていますし、一度作ってしまえば再利用も簡単なのでおすすめです。
下記の記事を参考にしていただけたら嬉しいです。
仮想環境は本当に一度作ってしまえば他の人とも共有できますし、
1週間前の状態に戻せたりと非常に便利ですよ。
インストール方法
pipでインストールすることができます。
簡単ですね。
pip install streamlit
インポート方法
これもpythonの通常の書き方です。 公式の記述どおり、略式は「st」で踏襲します
import streamlit as st
起動確認
起動確認用にデモページが用意されています。 下記のコマンドで実行できます。
streamlit hello
hello worldの名残ですね。 洒落たコマンドで個人的にこういうのは好きです。
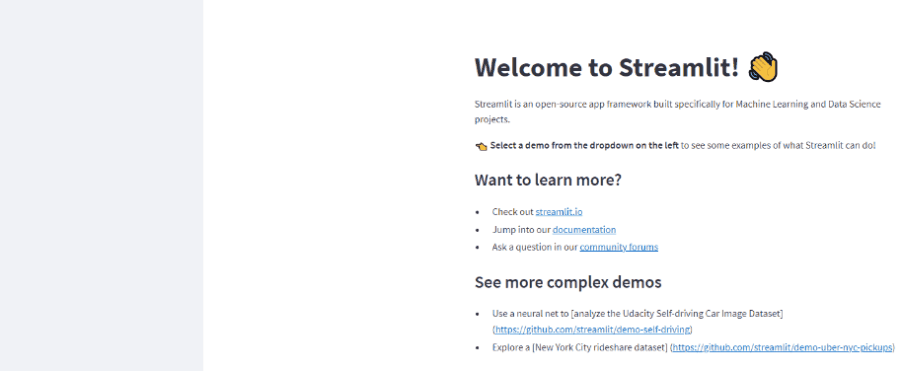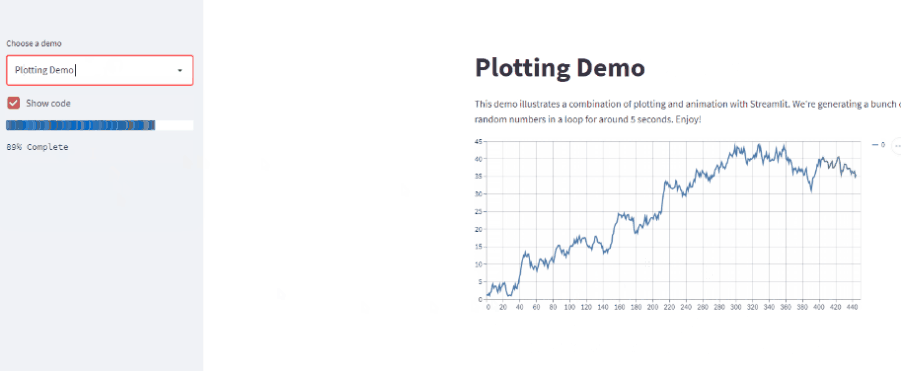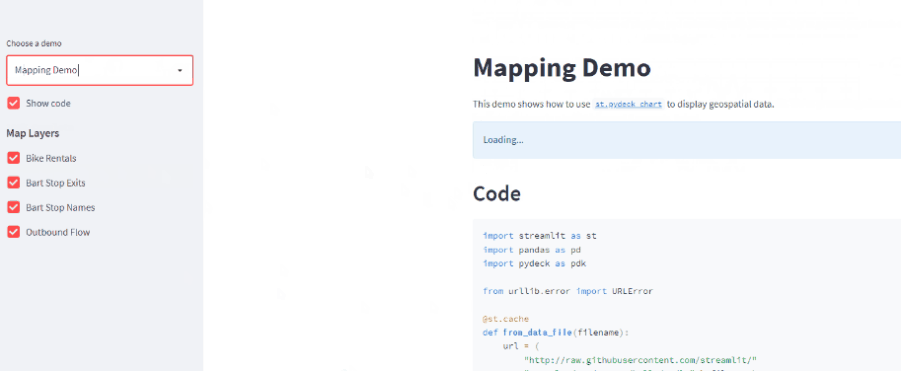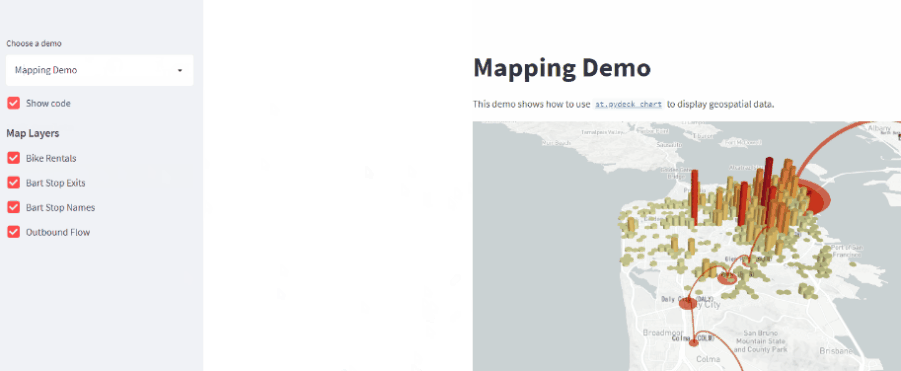
サンプルページがめちゃくちゃ整備されている
めちゃくちゃありがたいことにデモページにサンプルコードが紹介されています。 慣れている人はこれを応用して開発していけるので非常に便利ですね。 ここに書かれているコードをつなぎ合わせるだけでもちょっとしたデータビューワーは作れると思います。
基本的な使い方
ここからは、基本的な使い方を記載していきたいと思います。 ボタンやらスライドや選択ボックスとかも簡単にかけちゃいます。
タイトルの表示
ウェブページのh1タグに相当するものは下記で書けます。
st.title('title')
ちゃんと表示できてますね。
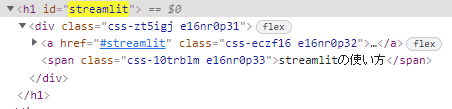
ちなみに、変換されたhtml文を見てみるとこんな感じ。
ボタンの表示
st.button('ボタン')
ダウンロードボタン
ダウンロードも簡単です。 処理したDataFrameをそのまま出力した場合は下記です。
list1=["a1","a2","a3"] df_sample=pd.DataFrame(data=list1) st.download_button( label='ダウンロードボタン', data=df_sample.to_csv().encode('utf-8'), file_name='sample.csv' )
はたまたローカルファイルをダウンロードしたい場合はopenを使えば可能です
list1=["a1","a2","a3"] df_sample=pd.DataFrame(data=list1) df_sample.to_csv('test.csv') st.download_button( label='ダウンロードボタン', data=open('test.csv)', file_name='sample.csv' )
最近のアップデートによって、ダウンロードボタンが標準実装されました。 以前は、html文を無理やり組みこむ必要がありましたが、今は必要ありません。 念のため古いバージョンを使わなければならない場合は下記でも対応可能です。
import base64 def main() #df_sampleは何かしらのpandasDataframe list1=["a1","a2","a3"] df_sample=pd.DataFrame(data=list1) csv = df_sample.to_csv(index=False) b64_coder = base64.b64encode(csv.encode()).decode() href = f'<a href="data:application/octet-stream;base64,{b64_coder}" download="result_utf-8.csv">ファイルのダウンロード</a>' st.markdown(f"CSVファイルのダウンロード(utf-8): {href}", unsafe_allow_html=True)
セレクトボックスを表示
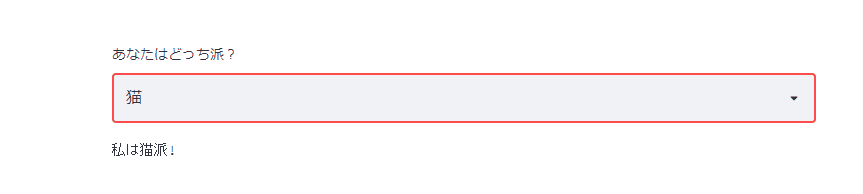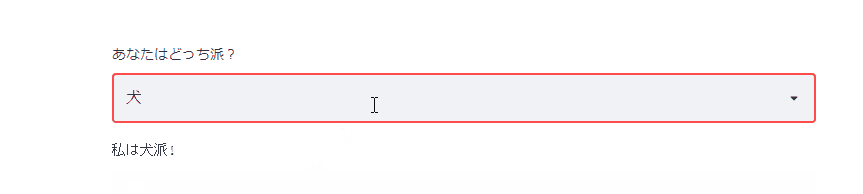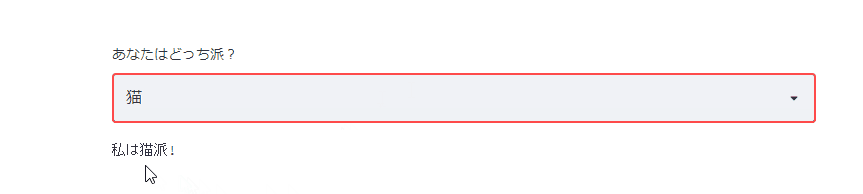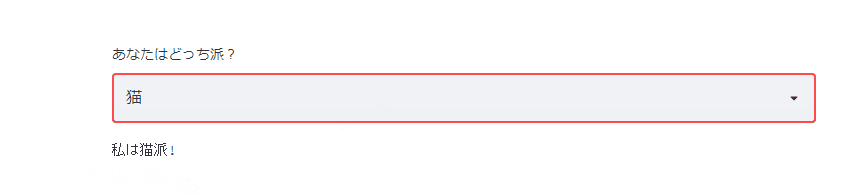
セレクトボックスも用意されています。
選んだものは変数として格納できます。
これで、ユーザーの選択に応じたデータの描画が可能となります。
list_animal=['犬','猫'] choice_animal=st.selectbox('あなたはどっち派?', list_animal ) st.text('私は'+choice_animal+'派!')
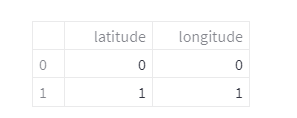
dataframe の中身を表示
df_pos = pd.DataFrame({'latitude':[0,1],'longitude':[0,1]})
st.dataframe(df_pos)
(表示例)
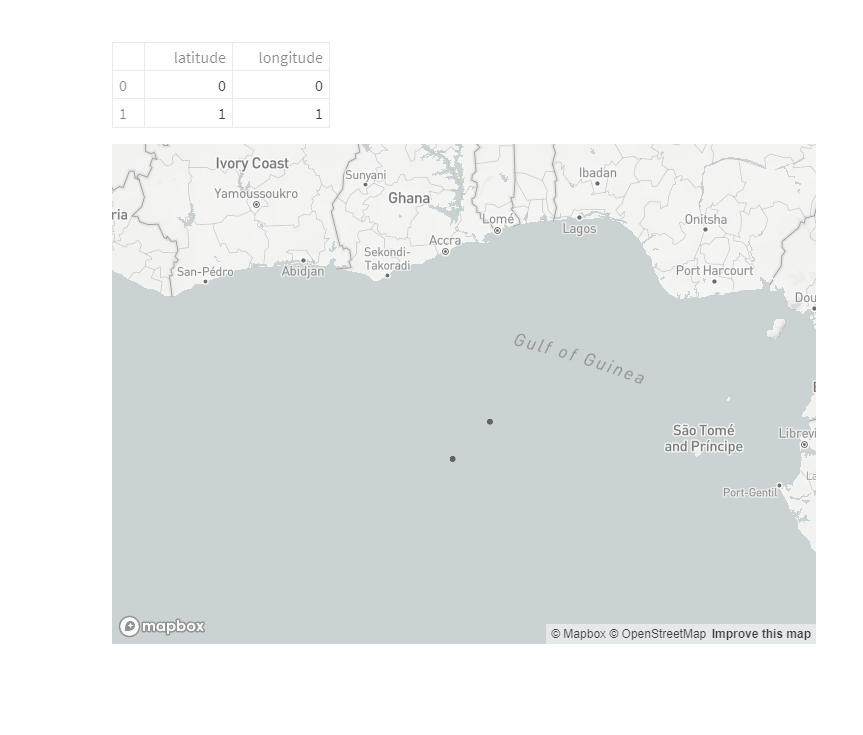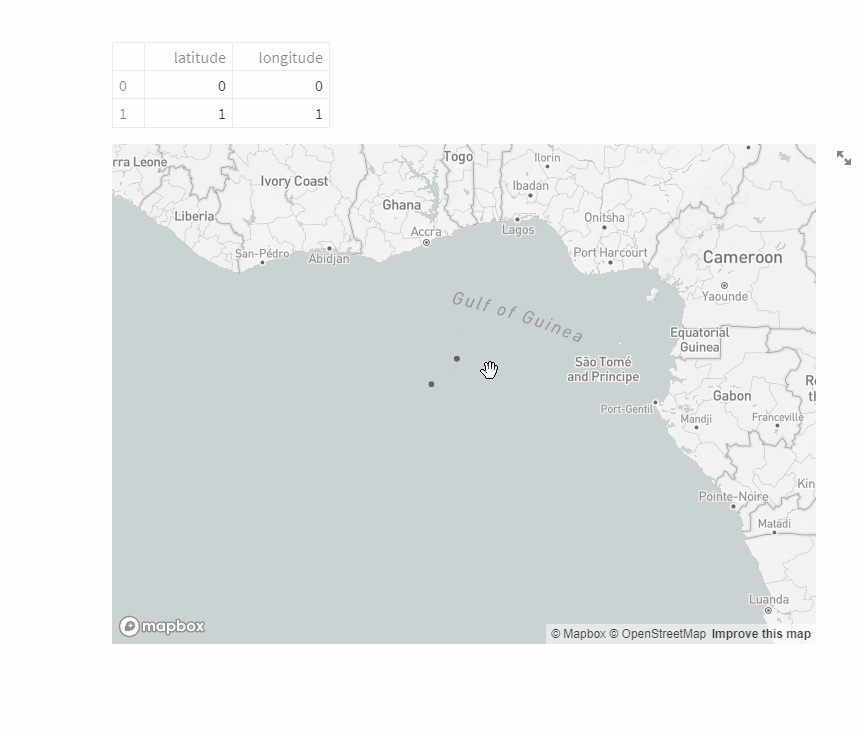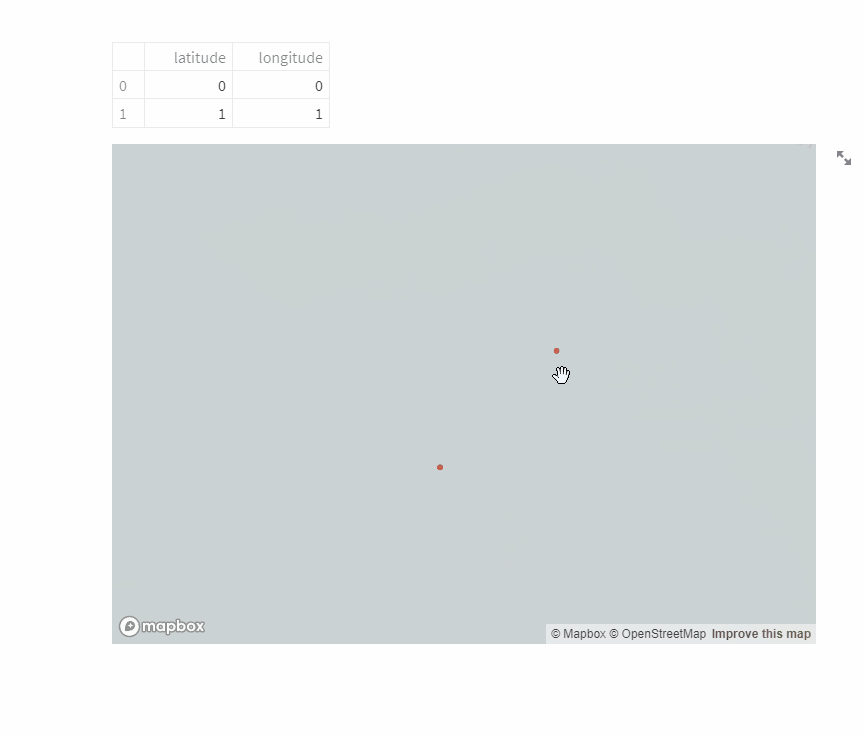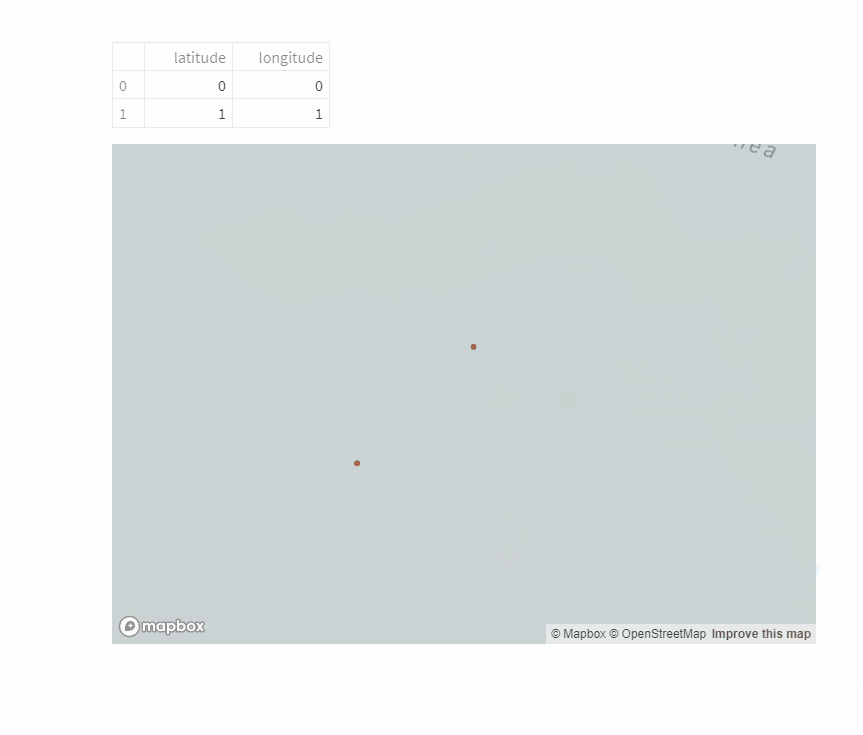
地図を表示
地図にデータを表示するといったことも1行でできます。
すごい世の中ですね。
df_pos = pd.DataFrame({'latitude':[0,1],'longitude':[0,1]})
st.dataframe(df_pos)
st.map(df_pos)
使う上での注意点:ボタンの画面を押すたびにファイルが全て実行される
使う上での注意点というより、自分が使っていて躓いた内容を記載したいと思います。
streamlit のでは、配置したボタンを押すたびに状態が初期化され、ファイルの先頭から順に実行します。
変数が全て初期化されてしまうので、慣れるまでは結構面倒くさかったですね。
自分は結構これになれるまでに時間がかかりました。
また、デバッガもデフォルトでは利用できないので、適宜変数の内容をブラウザに表示してデバッグするのが基本的な使い方となります。
これが案外面倒で、デバッガのありがたみを感じます。
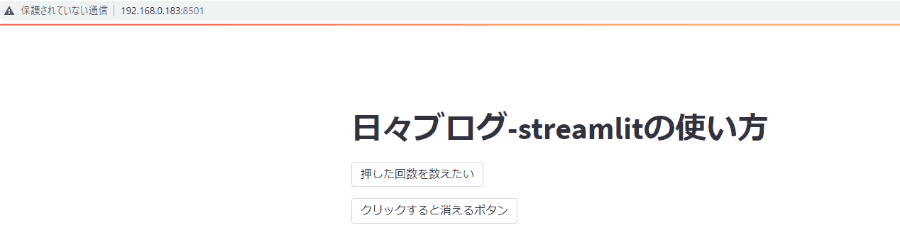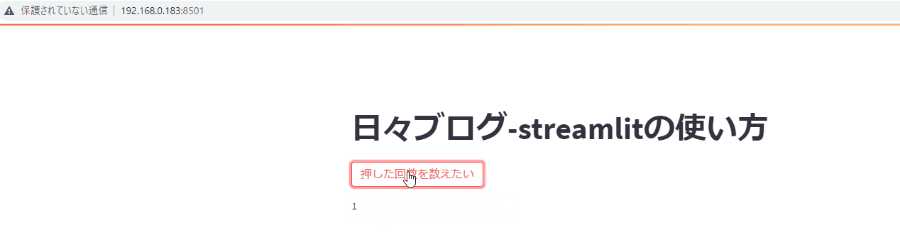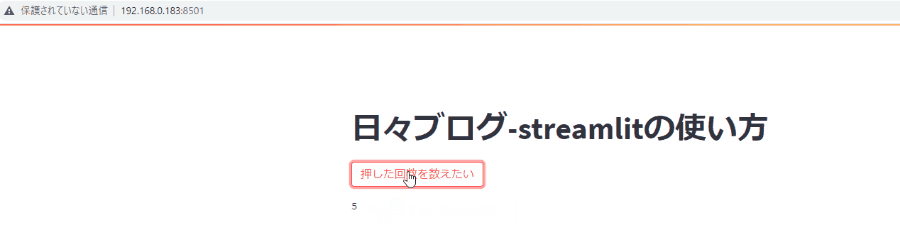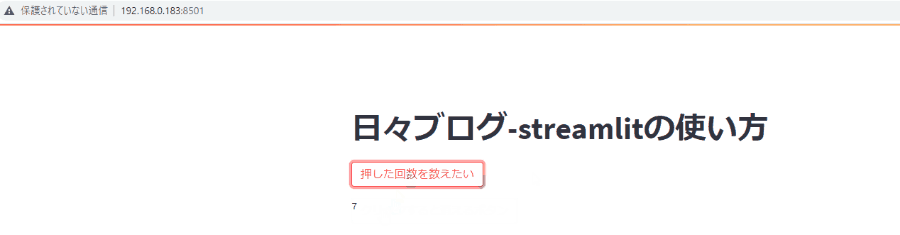
たとえば、下記のようなythonの書き方だと、ボタンを押した回数すらうまく表示できません。
ボタンを押したらTrueが返ってきてif文を通って1回ずつ足されそうですが、1より増えません。
これは、ファイルの一番上から処理が開始されてボタンを押すたびにbutton_countが0に代入されたあと、if文内で1が足されるからですね。
何だ!使えないじゃんというわけでも無く、しっかり回避策は用意されています。
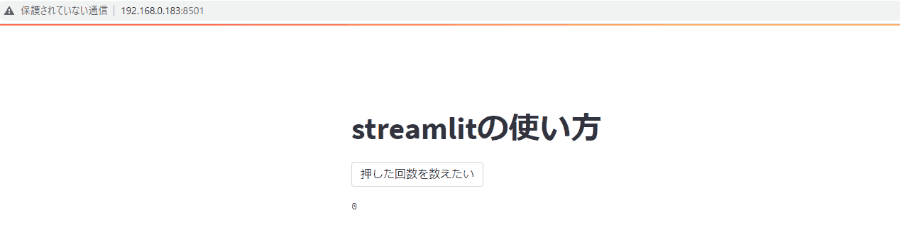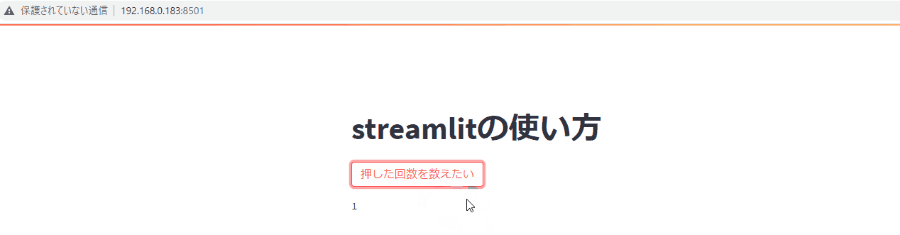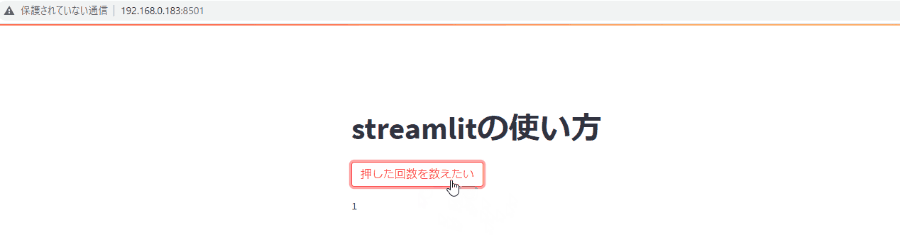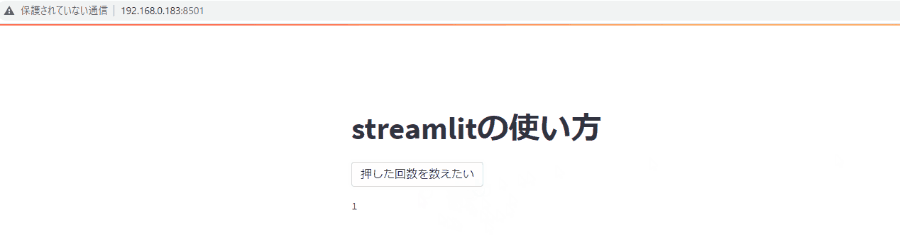
button_count=0 st.title('streamlitの使い方') is_click=st.button('押した回数を数えたい') if is_click: button_count=button_count+1 st.text(button_count)
画面更新しないかぎり変数を保存する方法
繰り返しになりますが、streamlitは画面でアクションを行うたびにファイルを一番上から実行し、このとき変数は初期化されてしまいます。
画面更新を行わない限り変数を保持し続けるには、session_stateを利用します。
if 'variable' not in st.session_state: st.session_state.variable = 0
1つや2つくらいの変数であれば、これで十分なのですが、管理したい変数が増えるたびにこれを書くのはすごく面倒ですよね。
状態を管理した画面部品が増えるたびにこれを実行していたのでは
可読性が激減するので、
個人的には下記の書き方がオススメです。
初回ロード時だけ重たいデータをダウンロードしたい場合など時間のかかる処理を1回だけ行いたい場合はこの書き方が便利。
状態管理しないと、画面を操作するたびにダウンロードしちゃいます。
def main(): st.title('日々ブログ-streamlitの使い方') is_click=st.button('押した回数を数えたい') if 'initial_load' not in st.session_state: # 初期化処理を示す状態変数 st.session_state.initial_load = True if st.session_state.initial_load: ### 初期状態を示す状態変数をFalse st.session_state.initial_load=False ### 最初の接続時だけやりたい処理。 st.button('クリックすると消えるボタン') st.session_state.initial_load=False st.session_state.button_count=0 if is_click: st.session_state.button_count=st.session_state.button_count+1 st.text(st.session_state.button_count)